Beyond Yes or No: The Middle Path of AI
Confident Lies vs Humble Truths
A Real Story
Imagine Anna, a small business owner. One day she asks an AI assistant, “What’s the current price of copper per ton?” The AI responds confidently, “$9,800 per ton,” even though the real price is closer to $10,200. Because the AI sounded certain, Anna trusts it, orders copper based on that number, and ends up losing money when the real price turns out higher.
Or imagine a student writing a term paper who asks the AI, “When did the ancient city of Hattusa fall?” The AI confidently gives a date—say, “1180 BCE”—but that is wrong. The student depends on that date, even if a quick check would have shown different estimates.
These are examples of hallucinations—when AI gives answers that sound real but are false. They matter because people rely on AI for real decisions: business, education, health, etc.
What Are Hallucinations in AI, and Why Do They Happen
- A hallucination is when an AI model, like ChatGPT, produces information that is confident and plausible-sounding, but is actually wrong or made up.
- Researchers at OpenAI have studied why LLMs (“large language models”) hallucinate. One key finding: the ways models are trained and evaluated reward guessing rather than admitting “I don’t know.”
- For example: imagine test questions. If you guess and sometimes get lucky, your score might look good. But if you often say “Unsure” when you don’t know, you might have fewer wrong answers—but also fewer right answers—so your test score can look worse. Most evaluations used in AI do not reward saying “I’m not sure.” They reward only being right.
OpenAI’s own studies show that these evaluation methods push AIs toward giving answers even when uncertain. So instead of being cautious, the model learns to act confident—even when it doesn’t know. That leads to more hallucinations.
What OpenAI’s Proposed Fix Is
OpenAI suggests changing how models are evaluated and scored. Key parts of their fix:
- Reward uncertainty / abstention: If the model doesn’t know something, it should be able to say so (“I’m not certain”) and be penalized less than if it confidently gives a wrong answer.
- Penalize confident errors more heavily than errors made while uncertain. So giving a false statement with high confidence would cause a bigger penalty than guessing.
- Change evaluation benchmarks (the tests AI models run on) so that they measure not only correctness, but also whether the model recognized when it didn’t know.
The idea is: if the model is rewarded for being honest about uncertainty, then it will avoid making up facts, or at least flag that it is unsure. That would reduce hallucinations.
The Argument: Why Fully Applying the Fix Might “Kill” ChatGPT
When people say this fix “would kill ChatGPT,” they mean it might dramatically change the user experience, cost structure, and competitiveness of the service. Here are the main arguments, with evidence, why:
- Users like confident answers.
Many users prefer an AI that appears sure—even if occasionally wrong—rather than one that often says “I’m unsure.” Confidence gives an impression of competence. If ChatGPT started admitting uncertainty very often, some users might lose trust or get frustrated and switch to another product.
- Operational cost goes up.
To determine when the model is uncertain, the system might need to do more work: compute more possible answers, check reliability, maybe verify with external sources, etc. That makes running the service more expensive. High confidence shortcuts are cheaper. - Evaluation benchmarks and competitive pressure.
AI companies often compete by showing how many questions their models answer correctly, how fast, how many features. If one company continues to use benchmarks that reward guessing, their product may look better on paper (even if less reliable). If OpenAI changes benchmarks, but competitors don’t, OpenAI might lose its leading position on charts, marketing, reputation. - Balancing truth vs usefulness.
There are many situations where an approximate answer is still useful—e.g., rough estimates, creative suggestions, brainstorming. If the model is too cautious, it may refuse to answer many questions, or only give vague responses. That could reduce its usefulness for users who want fast, concrete answers. - Economic sustainability.
Because of the increased compute cost and possibly fewer interactions (if users are unhappy), revenue per query might need to increase, or margins shrink. That challenges the business model of providing widespread access.
Thus, the worry is: if OpenAI fully implements the proposed evaluation changes (rewarding abstention, punishing confident lies), ChatGPT might become less “flashy,” less “sure,” more cautious. For many users that could feel like the system is weaker. If many users are disappointed, usage might drop, feedback loops might make it hard to sustain the platform as it now is.
Is the Fix Impossible or Just Difficult?
It is not that the fix is impossible—it has significant trade-offs. Some evidence:
- OpenAI’s research admits hallucinations still occur even in more advanced models, though at lower rates. So progress is real, but imperfect.
- Experts (for example, Wei Xing) have argued that these changes might make the model slower, more expensive, and potentially less appealing.
- There is a comparison: Claude (from Anthropic) tends to express uncertainty more often than some OpenAI models, which means fewer hallucinations—but Claude’s high “refusal rate” or saying “I don’t know” often can also reduce how useful it feels to some users.
So the challenge is a tension between reliability (honesty, fewer hallucinations) and usability/popularity (quick answers, confidence, smooth experience).
let’s expand the argument and ground it in three high-stakes domains: medicine, law, and education. This way, the general audience can see the concrete consequences of “fixing” hallucinations by making AI more cautious, and also the risks of leaving things as they are. I’ll rewrite the article in about 1,000 words, starting again with a real story, then moving into the three domains with examples and evidence.
When Honesty Hurts — and Saves: AI Hallucinations in Medicine, Law, and Education
A Real Story
It was late evening when Dr. Patel, a family physician, received a message from one of his patients, Maria. She had typed her symptoms into an AI chatbot before seeing him: headaches, fatigue, and some vision problems. The chatbot replied with confidence: “This is most likely multiple sclerosis. You should prepare for lifelong treatment.”
Maria spent the night crying, imagining her future. Yet when Dr. Patel ran tests, the truth was far less dramatic: she had a vitamin B12 deficiency, easily treatable with supplements. The AI’s answer wasn’t just wrong — it was damaging.
This is the danger of what experts call AI hallucinations: when a model like ChatGPT generates confident, convincing but false answers. And OpenAI has recently proposed a fix: reward AI systems for admitting “I don’t know” instead of pushing them to always give an answer.
But here is the trade-off: a cautious AI may save Maria from panic, yet it may also frustrate others who expect fast, confident responses. Let’s explore what this tension looks like in three crucial areas of human life — medicine, law, and education.
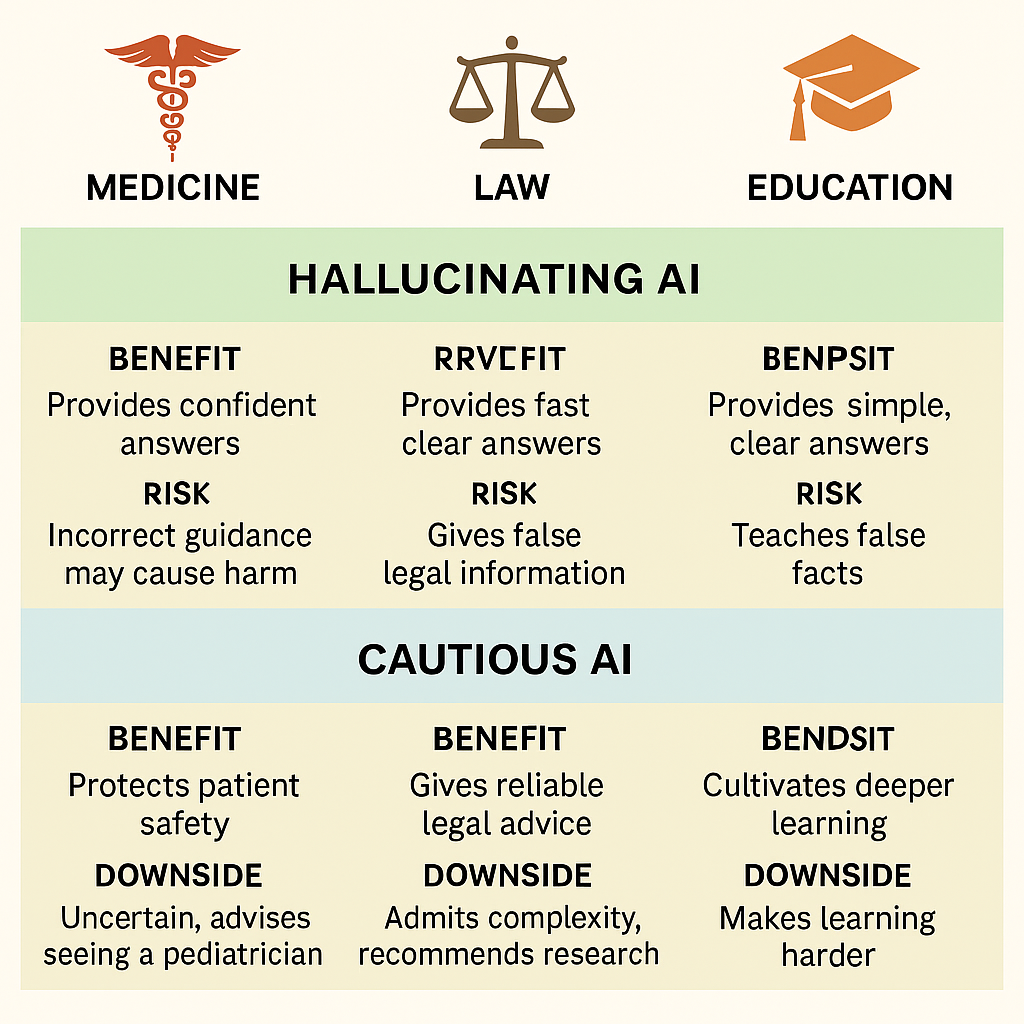
Medicine: Between False Alarms and Silent Risks
The Problem
AI in healthcare is rapidly advancing. Doctors use AI to interpret scans, triage patients, and even suggest treatments. But hallucinations can be deadly: a misdiagnosis delivered confidently could cause patients to delay seeking real help or start inappropriate treatments.
Example
Suppose an AI system is asked, “What is the best treatment for a persistent cough in a child?” If it confidently answers, “Give antibiotics immediately,” it risks contributing to antibiotic resistance and harming the child, since most coughs in children are viral and self-limiting.
The Trade-Off
- If we fix hallucinations (rewarding uncertainty): The AI might instead say, “I am not sure. Persistent cough can have many causes. Please consult a pediatrician.”
This protects the child but might frustrate parents looking for immediate guidance. - If we don’t fix hallucinations: Parents might follow wrong advice, leading to harm.
Proof of Evidence
A 2023 Mayo Clinic study found that 29% of AI chatbot medical responses contained factual inaccuracies or unsafe recommendations. At the same time, other research shows that patients like AI because it “sounds confident.”
So in medicine, the trade-off is stark: confidence vs safety.
Law: Between Bold Guidance and Dangerous Overreach
The Problem
Law is complex, with thousands of cases, statutes, and ever-changing interpretations. Lawyers, judges, and citizens are tempted to use AI to save time. But hallucinations here don’t just cause mistakes — they can have legal consequences.
Example
In 2023, two New York lawyers famously used ChatGPT to draft a legal brief. The AI confidently cited six prior cases as precedents. The problem? None of those cases existed. The court sanctioned the lawyers, damaging reputations and careers.
The Trade-Off
- If we fix hallucinations: A cautious AI might answer: “Legal precedent is complex. I cannot guarantee accuracy; please consult verified legal databases.”
This saves lawyers from disaster, but also makes the tool slower, more expensive, and seemingly “less helpful.” - If we don’t fix hallucinations: More lawyers may be misled, judges misinformed, and clients harmed.
Proof of Evidence
A 2024 Harvard Law Review survey showed that 60% of law students who used AI tools admitted they did not double-check every citation provided. The temptation to trust confident answers is high.
Here the trade-off is trustworthy caution vs speedy but risky guidance.
Education: Between Learning Support and Intellectual Laziness
The Problem
In classrooms worldwide, students use AI to write essays, explain math, or summarize history. The danger is not only wrong facts, but also the erosion of critical thinking.
Example
Imagine a student asks, “What caused the fall of the Roman Empire?” A hallucinating AI might confidently reply: “The Romans invented nuclear weapons, which destroyed their own empire.” Clearly false — but some students might copy it without question.
On the other hand, a cautious AI could answer: “Historians debate multiple causes, including economic decline, political instability, and invasions. I’m not certain which is most important.” That invites reflection, but many students might complain: “The AI doesn’t give me a clear answer!”
The Trade-Off
- If we fix hallucinations: Students learn to deal with uncertainty, weigh multiple perspectives, and think critically.
- If we don’t fix hallucinations: Students risk absorbing falsehoods uncritically, weakening education itself.
Proof of Evidence
A 2025 Stanford study found that high school students who used AI uncritically were more likely to repeat factual errors in essays than those who used AI cautiously or verified sources.
Here, the trade-off is deeper learning vs easy answers.
Why This Matters
Across these domains, the same theme emerges:
- Medicine: Safety may demand cautious AI, even if patients want certainty.
- Law: Accuracy matters more than speed, but pressure for confident guidance is strong.k
- Education: Truth and complexity should outweigh simplicity, but students may prefer shortcuts.
OpenAI’s proposed fix — rewarding AI for admitting uncertainty — might frustrate many users, but it could also prevent harm. Critics say this would “kill ChatGPT” because users love its smooth, confident voice. But in reality, the question is whether we want a friend who always sounds sure but lies sometimes, or one who admits doubt but is honest.
My Opinion: A Middle Path
Western thought, shaped by the Greeks, built its logic upon two pillars: the principle of the excluded middle — that every statement must be either true or false, never both, never neither — and the principle of non-contradiction, which forbids a thing from being and not being at the same time.
But the Buddha, in his luminous insight, offered a wider horizon. His Catuṣkoṭi (the fourfold logic) taught that reality is not bound to two rigid tracks. A statement may be true, or false, or both true and false, or neither true nor false. Logic, he showed, is not a one-legged crutch of binaries, but a four-directional compass pointing to the vastness of possibility.
Centuries later, quantum physics whispers in agreement: particles dwell in superposition, truths are smeared across probabilities, the fabric of reality resists being confined to yes or no. The Buddha’s path, once mystical, now finds validation in the equations of science.
Thus, in the debate over reason and its limits, the Buddha triumphs again. By rejecting the brittle rigidity of binary thinking, he offers the Middle Path — not narrow, not simplistic, but supple, inclusive, and alive. A logic not of exclusion but of depth, a cure not only for metaphysical blindness but also, perhaps, for the hallucinations of our machines.
I believe the answer is not “kill confidence” or “embrace hallucinations” but offer modes of use:
- In medicine and law: Default to high-caution mode — penalize confident errors harshly. An AI that guesses here is too dangerous.
- In education: Blend modes — encourage uncertainty, but also allow clarity when appropriate. Let AI explain multiple viewpoints.
- For casual use (recipes, poetry, brainstorming): Allow a creative mode where hallucinations are less dangerous and sometimes even helpful.
This way, Maria the patient, the New York lawyers, and the high school student each get what they need — safety, reliability, and growth.
Takeaways
The story of Maria’s false diagnosis shows how dangerous hallucinations can be. But in law and education, too, the costs of confident errors are real. OpenAI’s solution — training AI to admit uncertainty — may make systems slower, less flashy, and perhaps less “fun.” Yet across medicine, law, and education, the evidence suggests the long-term benefit of honesty outweighs the short-term thrill of confidence.
So the real question is not whether fixing hallucinations would “kill” ChatGPT. The question is whether we want our most powerful knowledge tool to be a smooth liar or a careful truth-teller. In high-stakes areas of life, the answer should be obvious. Here’s a visual infographic showing the trade-offs between hallucinating AI and cautious AI across medicine, law, and education. It summarizes the risks and benefits in each domain in a simple, reader-friendly way.
Here’s a visual infographic showing the trade-offs between hallucinating AI and cautious AI across medicine, law, and education. It summarizes the risks and benefits in each domain.
Discover more from RETHINK! SEEK THE BRIGHT SIDE
Subscribe to get the latest posts sent to your email.